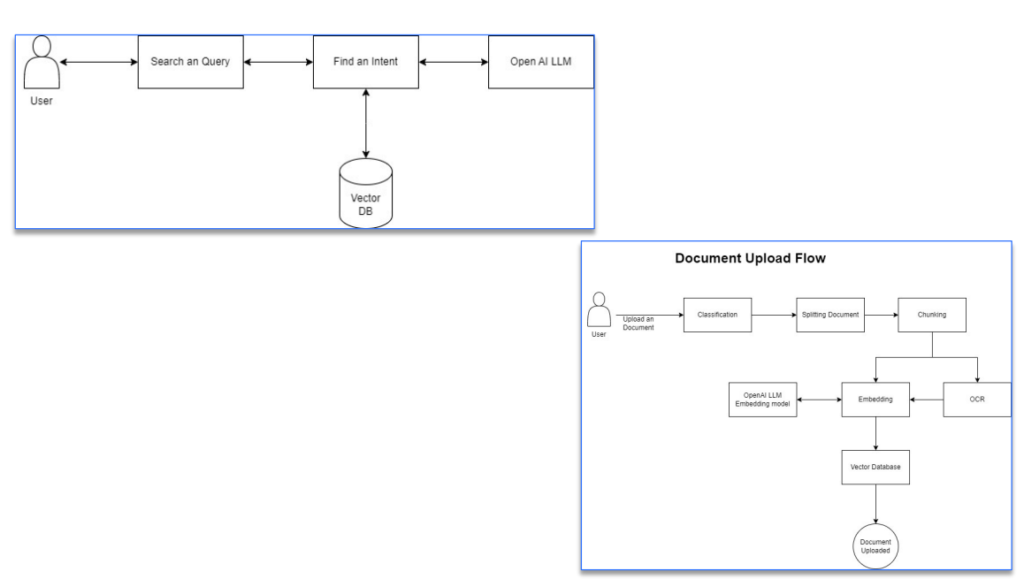
Data Ingestion: Documents were ingested from various sources into Azure Blob Storage.
Text Extraction and Translation:
• An Azure Function was triggered to extract text from the documents. • For PDFs or images, Azure AI Document Intelligence extracted the text.
Embedding Creation: Extracted text was chunked and converted into embeddings using the Azure OpenAI embedding model.
User Query and Retrieval:
• The query was converted into vector embeddings using the Azure OpenAI embedding model. • A vector similarity search in the vector database returned the top matching content. • The search results were presented as answers or used as grounding data for multi turn conversations.
Accuracy: Eliminated manual search efforts, resulting in accurate and relevant results.
Efficiency: Reduced search time significantly, improving overall productivity.
Insights: Enabled analytics on search patterns, helping identify trends and areas of interest.
Intelligent Document Search ChatBot [Cloud]
Overview: This scenario demonstrates a powerful document search experience that leverages the strengths of Azure Open AI ChatBot accepts instructions in plain natural language, such as English, and gives crisp and contextaware answers in seconds. The user can query any details related to the document. Framework: Llama Index, Flowise Vectors database: Qdrant, PineCone UI: React Backend: Python. Azure Services: Azure OpenAI, Azure Search, Azure Document Intelligence, Form Recognizer Embedding: Azure OpenAI GPT Model: gpt-4-turbo(1.76 trillion parameter), text-embeddingada-002 Hardware: Cloud-based AI-optimized compute instances.