Operating System – Red Hat 4.8.5-36 (Running on MS Hyperv VM)
Java Version – 1.8 (OpenJDK 64 Bit)
Solr Version – 6.6.5 (Single Instance without Zookeeper)
Core Name – UnifyNumDocs – 13,092,202
Size of Index – 25.7 GB
75thPcRequestTime – 165 ms
95thPcRequestTime – 672 msavgTimePerRequest – 142 ms
avgRequestsPerSecond – 2
JVM Setting – UseParNewGC & UseConcMarkSweepGC
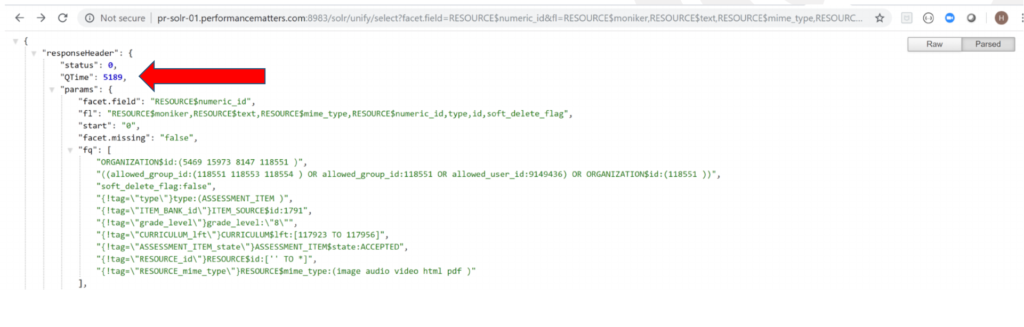
Before: 5.2 Seconds Query Response Time
Solution
Recommendation on JVM Setting (Add in Solr.in.sh file)
Recommendation on Solr Cache to be modified in SolrConfig.xml
Add docValues=true for these fields in schema.xml
As per the recommendation G1GC should be used with JDK 1.8 and above to get better memory usage. If possible MaxHeapSize should be set as 30 GB which is little bit higher than index size of 25.7 GB. Although there is limit of setting MaxHeapSize with OpenJDK, so we recommend to use Oracle JDK which have higher limit as compare to OpenJDK.
Given the size of index and number of documents it is recommended to use latest version of Solr and instead of single instance it should be Solr Cloud. As per the current index size and number of documents, it is recommended to create minimum 2 shards on Solr Cloud with minimum 2 instance of Solr and 3 instances of Zookeeper (should be on separate machine).
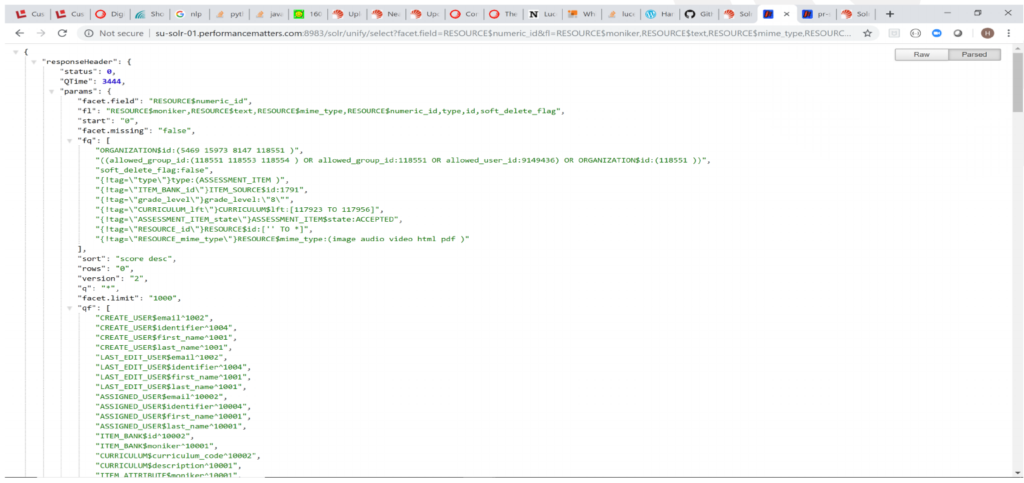
After: 3.4 Seconds 35% Reduction
Benefits Of Working With Nextbrick
Technical Expertise
Domain Expertise
Quality , team of Industry leading best practices experience Data Scientists and Solr Consultants
Speed: Fast onboarding , designing, and development , and solution delivery services
Cost: Low cost, flexible , negotiable as per budget and requirement
Quality: Ensure client goals are met as per acceptance and success criteria with most optimal solution