Transforming Enterprise Content into Searchable Knowledge
Our end-to-end ingestion pipeline converts your diverse information assets into optimized vector representations, forming the foundational layer of any effective RAG system. We process content from all major enterprise sources and prepare it for intelligent retrieval through sophisticated embedding and indexing strategies.
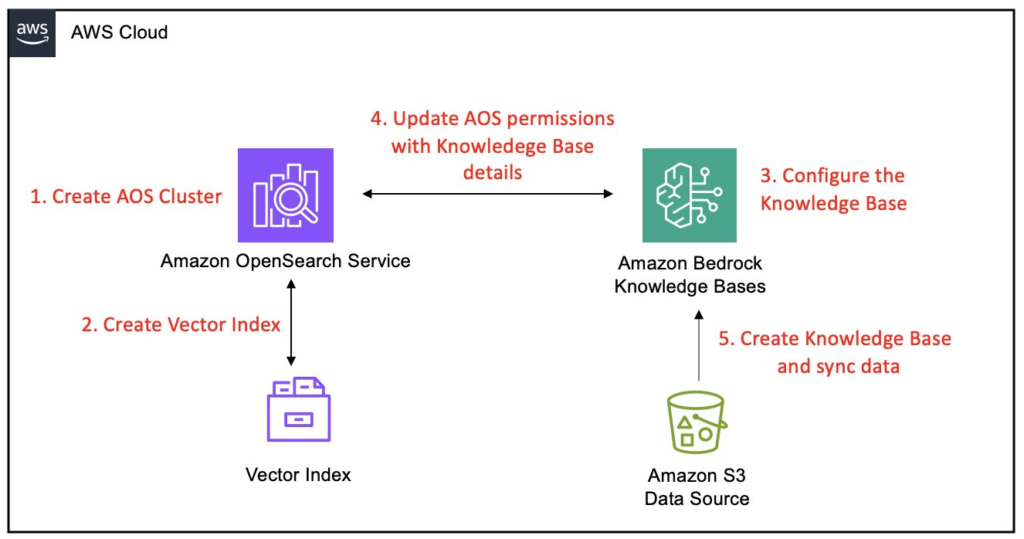
Core Components of Our Ingestion Architecture
1. Content Extraction & Normalization
Multi-format Processing Pipeline
We implement specialized parsers for every document type in your ecosystem:
- PDF documents (text and scanned/image-based)
- Microsoft Office formats (Word, Excel, PowerPoint)
- HTML web content and wikis
- Plain text files and markdown
- Database exports and API responses
- Email archives and chat transcripts
Metadata Enrichment Layer
Each document undergoes metadata extraction and enhancement:
- Source system identification and version tracking
- Document hierarchy and relationship mapping
- Quality scoring and duplicate detection
- Domain-specific tagging and classification
- Temporal metadata for time-sensitive content
2. Intelligent Chunking Strategies
Semantic-Aware Segmentation
Unlike naive text splitting, our chunking preserves logical coherence:
| Chunking Strategy | Best For | Key Benefit |
|---|---|---|
| Semantic Boundary Detection | Technical documentation | Preserves complete concepts |
| Recursive Character Splitting | Mixed-format content | Handles varied document structures |
| Fixed-size Overlapping Windows | Dense technical content | Maintains context continuity |
| Content-aware Segmentation | Legal/contract documents | Keeps clauses and sections intact |
Hierarchical Chunking Implementation
For complex documents, we implement parent-child relationships:
- Parent chunks capture broad context and document structure
- Child chunks contain specific details and granular information
- Relationship mapping enables multi-level retrieval
- Dynamic chunk assembly during query time
3. Advanced Embedding Generation
Model Selection & Optimization
We conduct thorough evaluation to select optimal embedding models:
Consideration Factors:
- Domain specificity (general vs. specialized models)
- Multilingual support requirements
- Embedding dimensionality and performance trade-offs
- Batch processing capabilities and throughput
- Cost-effectiveness for scale
Custom Embedding Solutions
For specialized domains, we implement:
- Fine-tuned embedding models on domain-specific corpora
- Ensemble embedding strategies combining multiple models
- Hybrid approaches mixing general and specialized embeddings
- Dynamic embedding selection based on content type
4. Vector Database Configuration & Indexing
Database Selection Matrix
We match vector database technology to your specific needs:
| Database Option | Best For | Key Features |
|---|---|---|
| Pinecone | Production-scale applications | Fully managed, high performance |
| Weaviate | Rich metadata filtering | Hybrid search capabilities |
| Chroma | Rapid prototyping | Easy to deploy and test |
| Qdrant | Geospatial applications | Advanced filtering options |
| Milvus | Billion-scale vectors | Distributed architecture |
Indexing Optimization Strategies
- HNSW (Hierarchical Navigable Small World): Fast approximate nearest neighbor search
- IVF (Inverted File Index): Efficient for large-scale deployments
- Product Quantization: Memory optimization for dense vectors
- Composite Indexes: Combining vector similarity with metadata filters
Implementation Workflow
Phase 1: Source Analysis & Pipeline Design
- Source System Assessment
- Inventory all data sources and formats
- Analyze content volume and growth patterns
- Identify access methods and authentication requirements
- Document regulatory and compliance constraints
- Pipeline Architecture Design
- Design scalable ingestion workflows
- Implement fault tolerance and retry logic
- Create monitoring and alerting systems
- Design backup and recovery procedures
Phase 2: Processing Pipeline Development
- Extraction Module Implementation
- Develop format-specific parsers
- Implement content cleansing and normalization
- Create metadata extraction routines
- Build quality validation checks
- Chunking Strategy Deployment
- Configure optimal chunk sizes per content type
- Implement overlap strategies for context preservation
- Develop semantic boundary detection
- Create chunk quality metrics and validation
Phase 3: Embedding & Indexing
- Embedding Pipeline Configuration
- Select and optimize embedding models
- Implement batch processing for efficiency
- Create embedding cache layers
- Develop embedding quality evaluation
- Vector Database Setup
- Configure database clusters and scaling
- Implement indexing strategies
- Set up replication and high availability
- Configure security and access controls
Phase 4: Quality Assurance & Optimization
- Quality Metrics Implementation
- Retrieval accuracy testing
- Chunk coherence evaluation
- Embedding similarity validation
- End-to-end pipeline performance testing
- Continuous Improvement Systems
- Automated pipeline monitoring
- Performance trend analysis
- Usage pattern feedback incorporation
- Incremental update mechanisms
Specialized Industry Solutions
Financial Services
- SEC Filing Processing: Automated extraction from complex financial documents
- Regulatory Document Indexing: Real-time updates for changing compliance requirements
- Research Report Analysis: Multi-source financial research consolidation
Healthcare & Life Sciences
- Medical Literature Processing: Structured extraction from research papers
- Patient Record Ingestion: HIPAA-compliant de-identification and chunking
- Clinical Guideline Indexing: Version-aware document management
Legal & Compliance
- Contract Analysis: Clause-level segmentation and metadata tagging
- Case Law Processing: Citation network mapping and relationship tracking
- Regulatory Update Pipeline: Automatic ingestion of new regulations
Performance & Scalability Features
Horizontal Scalability
- Distributed processing across multiple workers
- Dynamic resource allocation based on load
- Geographic distribution for global enterprises
- Elastic scaling for seasonal or peak demands
Performance Optimization
- Parallel Processing: Concurrent document processing streams
- Incremental Updates: Only process changed content
- Smart Caching: Frequently accessed vectors in memory
- Lazy Loading: On-demand retrieval of less-used content
Quality Control Mechanisms
- Automated Validation: Continuous pipeline health monitoring
- Human-in-the-Loop: Critical content review workflows
- A/B Testing: Compare different processing strategies
- Feedback Integration: User corrections improve pipeline over time
Security & Compliance Implementation
Data Protection
- End-to-end encryption for data in transit and at rest
- Secure credential management for source system access
- Role-based access control for pipeline components
- Complete audit logging of all processing activities
Regulatory Compliance
- GDPR/CCPA data handling protocols
- HIPAA compliance for healthcare data
- FINRA/SEC compliance for financial data
- Industry-specific certification support
Integration Capabilities
Source System Connectors
- Pre-built connectors for common enterprise systems
- Custom connector development for proprietary systems
- API-based integration for cloud services
- Database replication and change data capture
Output Flexibility
- Multiple vector database support
- Custom embedding format exports
- Metadata enrichment for downstream systems
- Real-time streaming updates for dynamic content
Monitoring & Management
Operational Dashboard
- Real-time pipeline performance metrics
- Content processing statistics and trends
- Error tracking and alerting systems
- Cost monitoring and optimization recommendations
Quality Analytics
- Retrieval success rate tracking
- Chunk quality scoring over time
- Embedding effectiveness measurements
- User satisfaction correlation analysis
Our Knowledge Base Ingestion & Vector Indexing solution ensures that your RAG system operates on clean, well-structured, and optimally indexed data—transforming your enterprise information into actionable intelligence with precision, speed, and reliability.