Unified Knowledge Retrieval Across All Content Types
We extend traditional RAG capabilities to handle diverse content modalities—text, PDFs, images, audio transcripts, and video summaries—creating a comprehensive knowledge retrieval system that understands and processes information across all formats. Our multi-modal RAG solutions enable enterprises to leverage their complete knowledge assets, regardless of format, through unified natural language interfaces.
Multi-Modal Architecture Framework
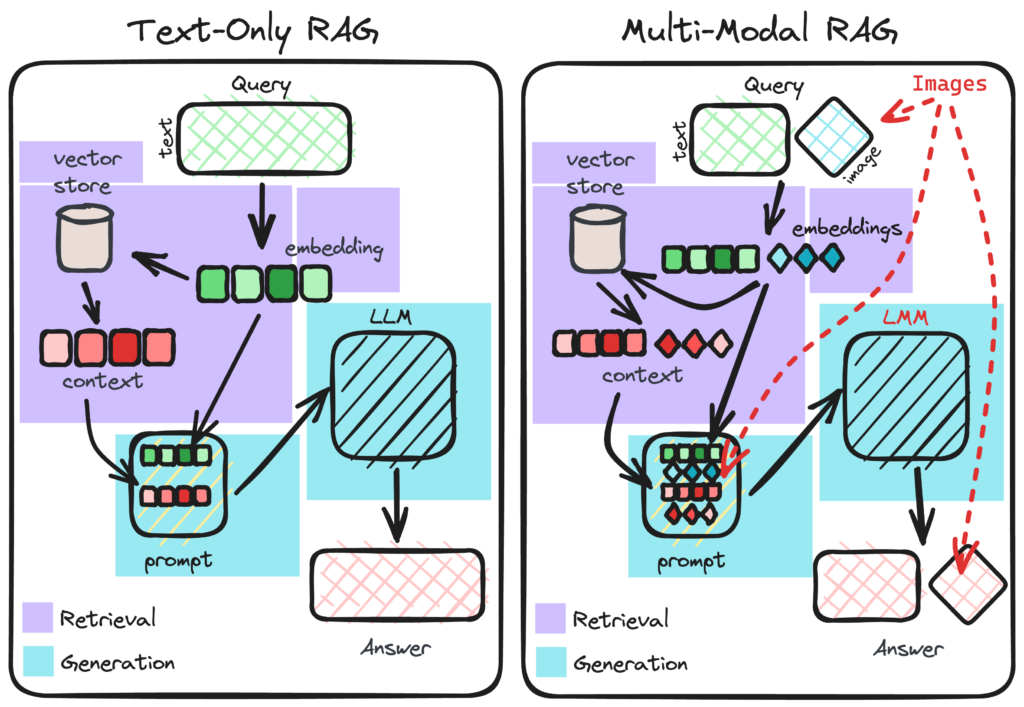
Unified Processing Pipeline
Multi-Modal Ingestion Architecture
Multiple Input Formats → Modality Detection → Specialized Processing → Unified Embedding → Vector Index
↓ ↓ ↓ ↓ ↓
Text, PDFs, Images, Identify Content Format-Specific Generate Cross- Store in Multi-
Audio, Video Type & Structure Extraction & Modal Vector Modal Vector
Processing Representations DatabaseText Document Processing
Advanced PDF & Document Handling
Intelligent PDF Processing
- Text Extraction: High-accuracy extraction from complex PDF layouts
- Preserved Structure: Maintain document hierarchy (headers, sections, lists)
- Table Recognition: Extract and structure tabular data with relationships
- Form Processing: Intelligent form field extraction and mapping
Document Type Support
- Business Documents: Contracts, reports, proposals, whitepapers
- Technical Documentation: Manuals, specifications, datasheets
- Archived Content: Scanned documents with OCR enhancement
- Structured Formats: Excel, PowerPoint, Word with metadata preservation
Processing Features
- Version Comparison: Track changes across document versions
- Cross-Document References: Link related content across multiple files
- Quality Scoring: Assess extraction quality and flag potential issues
- Incremental Updates: Process only modified sections of documents
Rich Text Understanding
Semantic Chunking Strategies
- Document-Aware Segmentation: Respect natural document boundaries
- Context Preservation: Maintain relationships between adjacent chunks
- Hierarchical Chunking: Parent-child relationships for nested content
- Entity-Aware Processing: Identify and link entities across documents
Image & Visual Content Processing
Intelligent Image Analysis
Computer Vision Integration
- Object Detection: Identify and tag objects within images
- OCR Enhancement: Extract text from images with high accuracy
- Scene Understanding: Interpret context and relationships in visual content
- Diagram Analysis: Extract information from charts, graphs, and schematics
Use Case Examples
User Query: "Find diagrams showing our network architecture"
→ Image Processing: Analyzes all technical diagrams in knowledge base
→ Object Recognition: Identifies network components (routers, switches, servers)
→ Text Extraction: Pulls labels and annotations from diagrams
→ Response: "Found 3 network architecture diagrams:
1. Core Network v3.2 (updated 2024)
2. Regional Office Deployment
3. Disaster Recovery Setup
Key components identified: Cisco routers, Juniper switches, Dell servers"Visual Document Processing
Mixed Content Handling
- Slide Decks: Extract text, speaker notes, and visual concepts
- Infographics: Understand data visualizations and key messages
- Screenshots: Contextual understanding of software interfaces
- Photographic Content: Scene description and object cataloging
Embedding Strategies
- Visual Embeddings: CLIP, ViT, or custom vision models
- Multi-Modal Fusion: Combine visual and textual representations
- Cross-Modal Retrieval: Text queries finding relevant images and vice versa
- Similarity Search: Find visually similar content across knowledge base
Audio Content Processing
Speech-to-Text & Audio Analysis
Audio Transcription Pipeline
Audio Files → Pre-processing → Speech Recognition → Speaker Diarization → Text Enrichment
↓ ↓ ↓ ↓ ↓
MP3, WAV, Noise Reduction Whisper, Identify Add Metadata,
Recordings & Normalization AssemblyAI, Different Timestamps,
Custom Models Speakers EmotionsAdvanced Audio Features
- Multi-Speaker Separation: Identify and separate different speakers
- Emotion & Sentiment Analysis: Detect tone and emotional context
- Keyword Spotting: Identify important terms and concepts
- Audio Summarization: Generate concise summaries of long recordings
Use Case Example: Meeting Intelligence
User Query: "What was decided about the Q3 product launch in last week's meeting?"
→ Audio Processing: Transcribes weekly product team meeting
→ Speaker Identification: Maps comments to specific team members
→ Decision Extraction: Identifies action items and decisions
→ Response: "In the 5/15 product meeting, decisions included:
• Sarah (Product Lead): Delay launch by 2 weeks for security review
• John (Engineering): Add two new features from customer feedback
• Mike (Marketing): Target launch date: August 15
Action items assigned with deadlines in meeting notes."Podcast & Broadcast Processing
Media-Specific Features
- Episode Segmentation: Break into logical segments by topic
- Guest Identification: Recognize and tag speakers/guests
- Theme Extraction: Identify main topics and discussion points
- Timestamp Linking: Connect concepts to specific time points
Video Content Processing
Comprehensive Video Analysis
Multi-Stage Video Processing
Video Files → Frame Sampling → Scene Detection → OCR & Object Recognition → Audio Transcription
↓ ↓ ↓ ↓ ↓
MP4, MOV, Extract Key Identify Scene Text from Transcribe
Streaming Frames (1-5/sec) Changes & Overlays & Dialogue &
Content Transitions Captions NarrationIntelligent Video Understanding
- Scene Classification: Categorize video segments by content type
- Action Recognition: Identify activities and processes shown
- Face Recognition: Tag individuals (with privacy considerations)
- Content Summarization: Generate concise video summaries
Use Case Example: Training Video Search
User Query: "Show me where we explain the new inventory management process"
→ Video Processing: Analyzes all training and process videos
→ Scene Detection: Identifies sections about inventory management
→ OCR Processing: Extracts text from slides and demonstrations
→ Response: "Found in 3 training resources:
1. Inventory System Training (Video, 15:30-22:45)
- Shows step-by-step process for new items
2. Quarterly Update Meeting (Video, 08:15-12:30)
- Explains process changes effective June 1
3. Quick Reference Guide (PDF with screenshots)
Key steps: Scanning → Validation → Location Assignment → System Update"Live & Streaming Video Support
Real-Time Processing
- Stream Analysis: Process live video feeds with low latency
- Event Detection: Identify important moments as they happen
- Real-time Transcription: Live captioning and note generation
- Alert Generation: Trigger notifications based on video content
Cross-Modal Integration & Retrieval
Unified Knowledge Representation
Cross-Modal Embedding Space
- Shared Vector Space: All modalities represented in common embedding space
- Cross-Modal Similarity: Measure similarity between different content types
- Modality-Agnostic Retrieval: Find relevant content regardless of original format
- Contextual Bridging: Connect related content across different modalities
Example Retrieval Flow
User Query: "Find information about our data center cooling systems"
→ Text Search: Finds documentation and reports
→ Image Search: Locates diagrams and photos of cooling infrastructure
→ Video Search: Identifies walkthrough videos and installation guides
→ Audio Search: Finds meeting discussions about cooling upgrades
→ Unified Response: Presents all relevant information with format indicatorsIntelligent Content Linking
Automatic Cross-References
- Content Relationships: Identify and link related content across formats
- Citation Networks: Track references between documents, images, and media
- Version Awareness: Connect different versions of the same content
- Complementary Content: Suggest related materials in different formats
Processing Pipeline Technical Implementation
Scalable Processing Infrastructure
Distributed Processing Framework
Content Queue → Modality Router → Specialized Workers → Result Aggregation → Vector Storage
↓ ↓ ↓ ↓ ↓
All Incoming Route to Appropriate Text, Image, Combine Store Unified
Content Processing Pipeline Audio, Video Results from Embeddings with
Processors All Modalities Format MetadataPerformance Optimization
- Parallel Processing: Simultaneous processing of different content types
- Priority Queueing: Process critical content first
- Resource Management: Allocate compute based on processing complexity
- Caching Strategy: Cache processed embeddings for frequently accessed content
Quality Assurance Pipeline
Multi-Modal Validation
- Cross-Modal Consistency: Verify information consistency across formats
- Processing Accuracy: Validate extraction quality for each modality
- Completeness Checking: Ensure all relevant content is processed
- Error Detection: Identify and flag processing failures
Automated Quality Metrics
- Text Extraction Accuracy: >98% for clean documents, >92% for complex layouts
- Image OCR Precision: >95% for standard fonts and layouts
- Audio Transcription WER: <5% Word Error Rate for clear recordings
- Video Processing Coverage: >90% of relevant frames analyzed
Industry-Specific Multi-Modal Solutions
Healthcare & Medical Applications
Medical Imaging Integration
- Radiology Image Analysis: Process and index medical imaging studies
- Clinical Documentation: Link notes with lab results and imaging
- Procedure Videos: Index surgical and procedure recordings
- Patient Education: Multi-format patient information retrieval
Manufacturing & Engineering
Technical Documentation
- Engineering Drawings: Process and understand technical schematics
- Equipment Manuals: Combine text, diagrams, and video instructions
- Inspection Reports: Link written reports with photographic evidence
- Training Materials: Unified access to all training formats
Education & Training
Learning Content Integration
- Lecture Recordings: Transcribe and index educational videos
- Slide Decks: Process presentations with speaker notes
- Textbook Analysis: Extract and index educational materials
- Interactive Content: Understand and reference interactive modules
Media & Entertainment
Content Production Support
- Script Analysis: Link scripts to final produced content
- Asset Management: Unified search across all production assets
- Archival Content: Process and index historical media
- Content Recommendation: Multi-modal content discovery
Security & Compliance Considerations
Privacy-Preserving Processing
Sensitive Content Handling
- PII Detection: Identify and protect personal information in all formats
- Content Redaction: Automatic redaction of sensitive visual/audio content
- Access Controls: Modality-specific permission management
- Audit Trails: Comprehensive logging of multi-modal access
Regulatory Compliance
Industry-Specific Requirements
- HIPAA Compliance: Medical image and recording protection
- GDPR/CCPA: Personal data handling across all content types
- Intellectual Property: Copyright and IP protection for multi-modal content
- Data Retention: Compliance with format-specific retention policies
Implementation Roadmap
Phase 1: Foundation (4-6 Weeks)
Core Text & PDF Processing
- Document processing pipeline implementation
- Basic text embedding and retrieval
- Quality assurance framework
- Initial monitoring and reporting
Phase 2: Visual Content (4-6 Weeks)
Image & Diagram Processing
- Computer vision integration
- Image embedding and indexing
- Cross-modal retrieval foundation
- User interface enhancements for visual content
Phase 3: Audio & Video (6-8 Weeks)
Media Processing Capabilities
- Audio transcription pipeline
- Video analysis implementation
- Multi-modal fusion techniques
- Performance optimization
Phase 4: Advanced Integration (Ongoing)
Enterprise-Specific Enhancements
- Custom modality support
- Advanced cross-modal features
- Performance scaling
- Industry-specific optimizations
Performance Metrics & SLAs
Processing Performance
- Document Processing: <30 seconds per 100 pages
- Image Processing: <10 seconds per high-resolution image
- Audio Transcription: Real-time + 10% processing time
- Video Analysis: 2x real-time processing speed
Retrieval Performance
- Multi-Modal Query Response: <2 seconds for complex queries
- Cross-Modal Retrieval Accuracy: >85% precision for relevant results
- Unified Result Ranking: Effective blending of different content types
- Scalability: Support for millions of multi-modal documents
Quality Metrics
- Content Coverage: >95% of enterprise knowledge processed
- Processing Accuracy: >90% across all modalities
- User Satisfaction: >4.2/5.0 for multi-modal search experience
- System Reliability: 99.5% uptime for processing pipelines
Integration with Existing Systems
Content Management System Integration
CMS Connectors
- SharePoint: Multi-modal content indexing
- Confluence: Page content and attachments
- Documentum/FileNet: Enterprise content management
- Custom CMS: API-based integration
Media Management Platforms
Digital Asset Management
- Adobe Experience Manager: Media asset integration
- Brandfolder/Widen: Marketing asset processing
- MediaValet: Video and image library access
- Custom Media Repositories: Direct integration
User Interface & Experience
Multi-Modal Search Interface
Unified Search Experience
- Format-Aware Results: Visually distinguish content types in results
- Previews & Previews: Thumbnails, audio snippets, video clips
- Cross-Format Navigation: Easy switching between related formats
- Interactive Results: Play audio/video directly from search results
Advanced Interaction Features
- Visual Querying: Upload image to find similar content
- Audio Queries: Voice-based search across all content
- Mixed-Modality Queries: Combine text and image in single query
- Context-Aware Filtering: Filter results by format, date, source, etc.
Business Impact & ROI
Efficiency Gains
- Knowledge Discovery: 60-80% faster information finding
- Training Time Reduction: 40-50% less time spent searching for materials
- Content Utilization: 3-5x increase in existing content usage
- Decision Support: Faster access to comprehensive information
Cost Optimization
- Reduced Duplication: Less recreation of existing content
- Improved Productivity: Less time wasted searching across systems
- Better Resource Utilization: Higher ROI on existing content investments
- Reduced Training Costs: More effective use of existing training materials
Support & Evolution
Continuous Improvement
- New Modality Support: Adding emerging content types
- Processing Enhancements: Improved accuracy and efficiency
- Integration Expansion: More system connectors and APIs
- Feature Development: New multi-modal capabilities based on user feedback
Enterprise Support
- 24/7 Monitoring: System health and performance
- Regular Updates: Security and feature enhancements
- Capacity Planning: Scaling support for growing content volumes
- Custom Development: Enterprise-specific modality support
Our Multi-Modal RAG Enablement transforms how organizations interact with their complete knowledge ecosystem, breaking down format barriers to create truly comprehensive intelligence systems that understand and retrieve information in whatever form it exists—text, images, audio, or video—delivering complete answers from your complete knowledge base.