Comprehensive Observability for Enterprise RAG Operations
We implement enterprise-grade MLOps and monitoring solutions that provide full-stack observability across your RAG systems—from vector store performance and model behavior to indexing freshness and cost optimization. Our platform ensures reliability, performance, and cost-efficiency through comprehensive monitoring, alerting, and automated optimization.
Full-Stack Monitoring Architecture
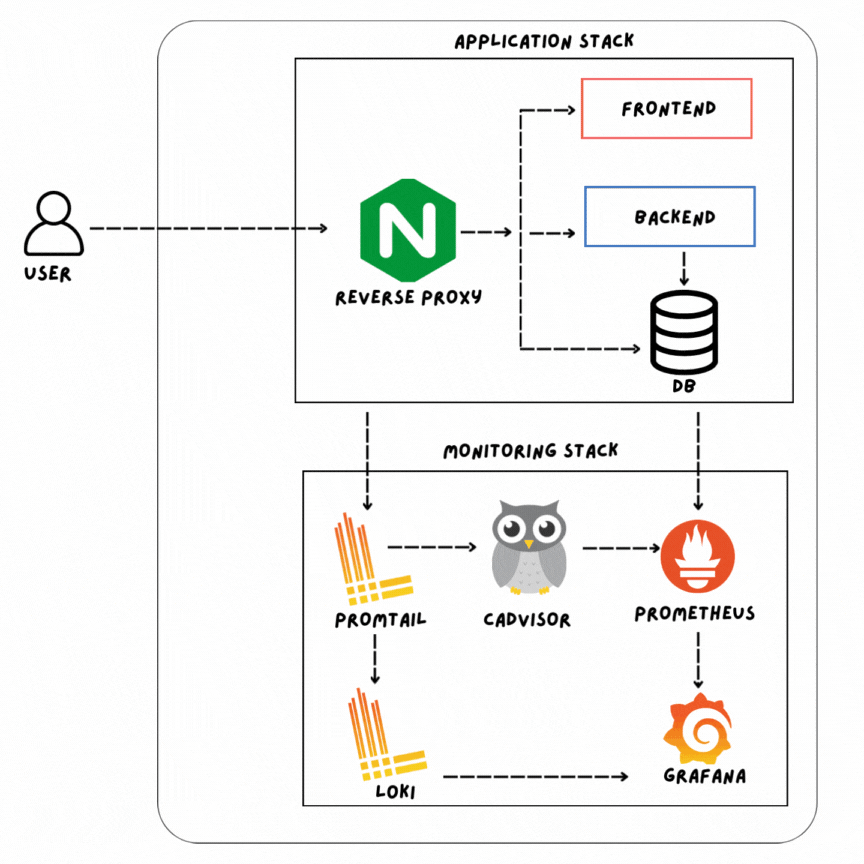
Multi-Layer Observability Framework
Comprehensive Monitoring Stack
Application Layer → Processing Layer → Infrastructure Layer → Business Layer
↓ ↓ ↓ ↓
User Interactions LLM & Retrieval Compute & Storage Business Impact
Query/Response Performance Resources & ROI Metrics
Latency, Errors Accuracy, Recall Utilization, Cost Satisfaction, ValueVector Store Monitoring
Performance & Health Metrics
Vector Database Health Monitoring
- Connection Health: Active connections, timeouts, error rates
- Query Performance: Latency percentiles (p50, p90, p99)
- Write Throughput: Indexing speed and write operations/second
- Memory Utilization: Cache hit rates and memory allocation
Key Performance Indicators
Metric | Target SLA | Alert Threshold
----------------------------|--------------------|-----------------
Query Latency (p95) | <200ms | >300ms
Indexing Freshness | <5 minutes | >15 minutes
Cache Hit Rate | >85% | <70%
Error Rate | <0.1% | >1%
Availability | 99.9% | <99%Storage & Index Health
Index Quality Monitoring
- Vector Index Integrity: Regular consistency checks
- Embedding Distribution: Monitoring for embedding drift
- Index Fragmentation: Measurement and optimization scheduling
- Storage Growth: Tracking vector store size and growth trends
Automated Health Checks
- Daily index validation and repair scheduling
- Embedding quality drift detection
- Performance degradation early warning
- Capacity planning alerts
Model Behavior Monitoring
LLM Performance Tracking
Generation Quality Metrics
- Response Quality Scores: Automated scoring (1-5 scale)
- Hallucination Rate: Percentage of unsupported claims
- Relevance Scoring: Query-response alignment measurement
- Tone & Style Consistency: Brand voice adherence
Real-Time Quality Monitoring
Live Query → Quality Assessment → Score Recording → Trend Analysis → Alerting
↓ ↓ ↓ ↓ ↓
User Input Multiple Quality Store in Time- Identify Notify on
Dimensions: Series Database Degradation Quality Drops
Accuracy, Relevance, Patterns Below Threshold
Coherence, CompletenessCost & Efficiency Monitoring
LLM API Cost Tracking
- Token Usage Analytics: Input/output token tracking by model
- Cost per Query: Real-time cost calculation
- Model Efficiency: Performance vs. cost analysis
- Budget Forecasting: Predictive spending based on usage trends
Cost Optimization Dashboard
Daily Spend Tracking → Model Comparison → Optimization Recommendations → Auto-Scaling
↓ ↓ ↓ ↓
Actual vs. Budget GPT-4 vs. Claude Switch Models for Adjust Model Selection
vs. Llama Cost/ Certain Query Types Based on Load & Budget
Performance Caching Strategies RemainingIndexing Freshness & Data Pipeline Monitoring
Content Pipeline Health
Ingestion Pipeline Monitoring
- Document Processing Latency: End-to-end processing time
- Pipeline Throughput: Documents processed per hour
- Error Rates by Source: Source-specific failure tracking
- Data Quality Metrics: Completeness and accuracy scores
Freshness Indicators
- Last Update Timestamp: Age of most recent index update
- Source Synchronization Lag: Delay between source change and index update
- Update Coverage: Percentage of changed content processed
- Priority Processing: Tracking of critical update handling
Automated Freshness Assurance
Scheduled Health Checks
Hourly: Pipeline throughput verification
Daily: Complete index freshness assessment
Weekly: Source synchronization validation
Monthly: Full reindexing quality verificationAlerting Rules
- Critical content >24 hours stale
- High-priority content >1 hour stale
- Pipeline failures >5 consecutive attempts
- Throughput drop >30% from baseline
Query Analytics & User Behavior Monitoring
Query Performance Analytics
Query Pattern Analysis
- Most Frequent Queries: Top queries by volume
- Failed Queries: Queries with low satisfaction or errors
- Query Complexity: Distribution of simple vs. complex queries
- Peak Usage Patterns: Time-based query volume analysis
Performance Correlation
- Query type vs. response quality
- Complexity vs. latency
- User segment vs. satisfaction
- Time of day vs. performance
User Experience Monitoring
Satisfaction Metrics
- Explicit Feedback: Direct user ratings (1-5 stars)
- Implicit Signals: Engagement metrics (follow-up questions, session length)
- Escalation Rate: Percentage requiring human intervention
- Retention Metrics: User return rates and frequency
Experience Score Calculation
User Experience Score =
(Satisfaction Rating × 0.4) +
(Engagement Score × 0.3) +
(Task Success Rate × 0.2) +
(Response Time Score × 0.1)Cost Optimization & Resource Management
Infrastructure Cost Monitoring
Cloud Resource Tracking
- Compute Cost: CPU/GPU utilization vs. cost
- Storage Cost: Vector store and cache storage costs
- Network Cost: Data transfer and API call expenses
- Total Cost of Ownership: Complete operational cost analysis
Cost Allocation
- Cost by department/team
- Cost by use case/application
- Cost by user segment
- ROI calculation per investment
Automated Optimization
Smart Scaling Strategies
- Load-Based Scaling: Automatic resource adjustment
- Time-Based Optimization: Pre-scale for known peaks
- Cost-Performance Balance: Optimal configuration selection
- Spot Instance Utilization: Cost-saving opportunities
Optimization Recommendations
Current State → Analysis → Recommendations → Implementation → Savings Validation
↓ ↓ ↓ ↓ ↓
Monitor Usage Identify Specific Changes Automated or Measure Actual
& Costs Waste & (Model Switches, Manual Actions Cost Reduction
Opportunities Resource Rightsizing, & Performance
Caching Strategies) ImpactAlerting & Incident Management
Multi-Level Alerting System
Alert Severity Levels
CRITICAL: System downtime or severe degradation
HIGH: Performance below SLA or quality issues
MEDIUM: Warning signs or trending problems
LOW: Informational or optimization opportunitiesAlert Channels
- PagerDuty/Opsgenie: Critical incident management
- Slack/Teams: Team notifications and collaboration
- Email: Daily/weekly summary reports
- Dashboard: Real-time alert visualization
Automated Incident Response
Self-Healing Capabilities
- Automatic Retry: Transient failure recovery
- Failover Routing: Switch to backup systems
- Resource Reallocation: Dynamic resource adjustment
- Cache Warming: Proactive cache population
Incident Playbooks
- Pre-defined response procedures
- Escalation paths and responsibilities
- Communication templates
- Post-incident analysis automation
MLOps Pipeline Integration
Continuous Integration/Deployment
Model & Pipeline CI/CD
Code Commit → Automated Testing → Staging Deployment → Canary Release → Production
↓ ↓ ↓ ↓ ↓
Git Push Unit & Integration Test with Real Gradual Rollout Full Deployment
Tests, Performance Data, Validation (5% → 20% → with Monitoring
Benchmarks, Safety against Metrics 50% → 100%) & Rollback Ready
ChecksVersion Control & Rollback
- Model version tracking
- Pipeline configuration versioning
- One-click rollback capabilities
- A/B testing framework integration
Experiment Tracking & Management
ML Experiment Platform
- Parameter Tracking: Hyperparameters and configuration
- Performance Comparison: Model version performance analysis
- Artifact Management: Model weights, embeddings, indexes
- Reproducibility: Complete experiment replication
Experiment Dashboard
Experiment → Parameters → Metrics → Artifacts → Comparison → Promotion
↓ ↓ ↓ ↓ ↓ ↓
Unique ID Config Used Results Saved Files Side-by-Side Deploy Best
(Model, (Accuracy, (Models, Analysis of Performing
Embeddings, Latency, Embeddings, All ExperimentsVersion to
Chunking) Cost) Indexes) Across DimensionsProductionDashboard & Visualization
Executive Dashboard
High-Level Overview
- System Health Score: Composite health indicator
- Cost Efficiency: ROI and value metrics
- User Satisfaction: Overall experience scores
- Reliability Metrics: Uptime and performance compliance
Business Impact Visualization
Monthly Value Delivered =
(Time Saved × Hourly Rate) +
(Errors Avoided × Cost per Error) +
(Decisions Accelerated × Value per Decision)Technical Dashboard
Real-Time Metrics Display
- Live Query Tracking: Active queries and performance
- Resource Utilization: CPU, memory, GPU, storage
- Error Rate Monitoring: Real-time error detection
- Cost Tracking: Live spending against budget
Interactive Analytics
- Drill-down capabilities to individual queries
- Comparative analysis across time periods
- Correlation analysis between metrics
- Predictive trend visualization
Compliance & Audit Monitoring
Regulatory Compliance Tracking
Compliance Verification
- Data Privacy: PII handling and GDPR/CCPA compliance
- Industry Regulations: HIPAA, FINRA, SOX requirements
- Access Logging: Complete audit trail of all operations
- Data Retention: Policy adherence and cleanup
Automated Compliance Reports
- Daily compliance status checks
- Monthly compliance certification
- Incident-based compliance impact assessment
- Audit preparation automation
Security Monitoring
Security Event Detection
- Unauthorized Access: Suspicious query patterns
- Data Leakage Prevention: Sensitive information detection
- API Abuse Detection: Rate limiting and anomaly detection
- Vulnerability Scanning: Regular security assessment
Predictive Analytics & Forecasting
Performance Forecasting
Capacity Planning
- Usage Growth Prediction: Query volume forecasting
- Resource Requirement Projection: Compute/storage needs
- Cost Forecasting: Budget planning and optimization
- Performance Trend Analysis: Future performance prediction
Early Warning Systems
- Predictive alerts before SLA breaches
- Capacity exhaustion warnings
- Cost overrun predictions
- Quality degradation forecasting
Anomaly Detection
Advanced Anomaly Detection
- Statistical Anomalies: Deviation from normal patterns
- Pattern-Based Detection: Unusual query or response patterns
- Cross-Metric Correlation: Multi-metric anomaly identification
- Machine Learning Models: Predictive anomaly detection
Automated Root Cause Analysis
Anomaly Detected → Pattern Analysis → Correlation Check → Root Cause Identification → Resolution Suggestions
↓ ↓ ↓ ↓ ↓
Metric Deviation Historical Pattern Related Metrics Most Likely Cause Recommended Action
Detected Comparison Analysis Identification (Restart, Scale, Fix)Implementation Roadmap
Phase 1: Foundation Monitoring (4-6 Weeks)
Core Monitoring Implementation
- Basic health and performance monitoring
- Error tracking and alerting
- Cost tracking foundation
- Basic dashboard setup
Key Deliverables
- Real-time system health dashboard
- Alerting for critical failures
- Daily performance reporting
- Cost tracking by component
Phase 2: Advanced Analytics (6-8 Weeks)
Comprehensive Monitoring
- Advanced performance analytics
- User behavior tracking
- Quality metrics implementation
- Predictive capabilities
Key Deliverables
- Multi-dimensional performance analysis
- User satisfaction scoring
- Quality degradation detection
- Capacity planning tools
Phase 3: Optimization & Automation (Ongoing)
Intelligent Operations
- Automated optimization
- Self-healing capabilities
- Advanced forecasting
- Continuous improvement
Key Deliverables
- Cost optimization automation
- Performance self-tuning
- Advanced anomaly detection
- Business impact analytics
Success Metrics & KPIs
Operational Excellence Metrics
- System Uptime: 99.9% availability
- Query Latency: <2 seconds p95 response time
- Cost Efficiency: <$0.10 per query average cost
- Mean Time to Detection (MTTD): <5 minutes for critical issues
- Mean Time to Resolution (MTTR): <30 minutes for critical issues
Quality & Reliability Metrics
- Accuracy Rate: >90% correct responses
- User Satisfaction: >4.0/5.0 average rating
- Index Freshness: <5 minutes for critical content
- Error Rate: <0.1% failed queries
Business Impact Metrics
- ROI: >3x return on investment
- Time Savings: >5 hours per user monthly
- Cost Reduction: >30% vs. manual alternatives
- Adoption Rate: >70% target user adoption
Support & Continuous Improvement
Ongoing Management
- 24/7 monitoring and support
- Regular system optimization
- Monthly performance reviews
- Quarterly strategic planning
Evolution & Scaling
- New metric development
- Advanced analytics implementation
- Integration with additional systems
- Scaling for increased loads
Our Monitoring & MLOps for RAG solution provides the essential operational intelligence and automation needed to run enterprise RAG systems at scale—ensuring reliability, performance, cost-efficiency, and continuous improvement through comprehensive observability and intelligent operations management.