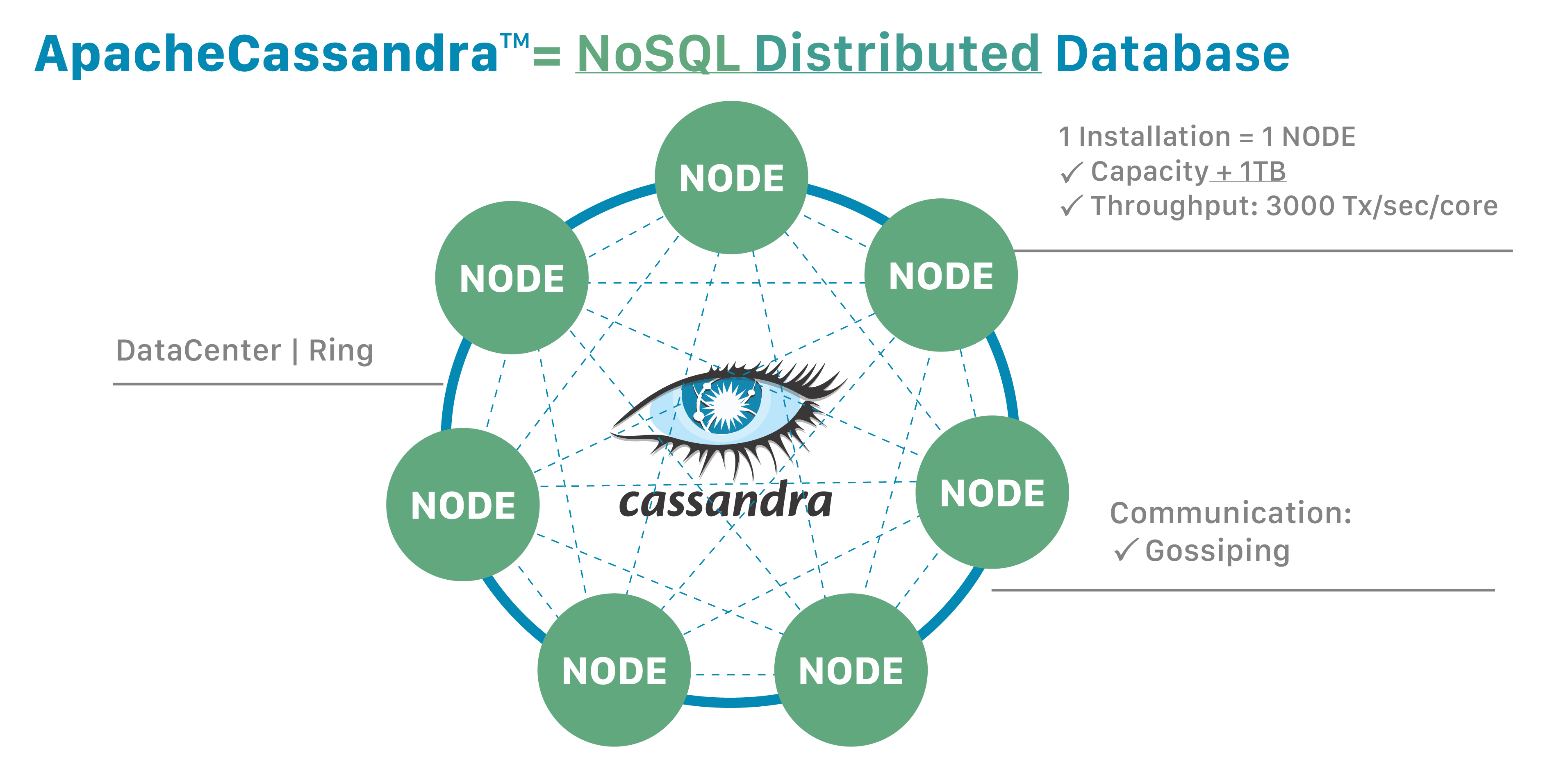
Cassandra
We provide enterprise-grade Apache Cassandra consulting, implementation, optimization, and 24/7 support services to ensure your mission-critical NoSQL databases deliver relentless performance, zero downtime, and predictable scaling.
Get a Free Cassandra Health & Performance Audit →
Why Apache Cassandra is the Foundation for Modern, Data-Intensive Applications
In an era defined by real-time data, global user bases, and relentless uptime requirements, traditional databases fail at scale. Apache Cassandra’s masterless, distributed architecture is engineered for linear scalability, fault tolerance, and continuous availability—handling petabytes of data across global data centers with no single point of failure.
The Critical Business Challenges Solved by Expert Cassandra Architecture:
Preventing Costly Downtime: A single hour of database downtime can cost enterprises $300K+. Cassandra’s inherent high availability prevents revenue loss and protects brand reputation.
Taming Explosive Data Growth: IoT streams, user interactions, and transactional logs create data volumes that double yearly. Cassandra scales horizontally by simply adding nodes, avoiding painful re-architecting.
Ensuring Global Performance: Users in Tokyo experience the same sub-millisecond latency as users in New York with multi-region, active-active replication.
Overcoming Operational Complexity: Misconfigured clusters, poor data modeling, and lack of expert Cassandra support lead to performance degradation, data inconsistency, and escalating cloud bills.
The Nextbrick Difference: Beyond Installation to Operational Excellence
We don’t just set up clusters; we embed database reliability engineering (DBRE) principles into your operations. Our Apache Cassandra consulting ensures your data layer becomes a competitive advantage, not a constant firefight. We deliver:
Predictable Performance at Petabyte Scale: Achieve consistent P99 read/write latencies under 10ms, even during 10x traffic spikes.
Cost-Optimized Cloud & On-Prem Deployments: Right-size your infrastructure, reducing AWS/Azure/GCP spend by 25-40% through expert tuning and reserved instance strategies.
Proactive Risk Mitigation: Our Cassandra support includes predictive analytics to identify bottlenecks, security vulnerabilities, and hardware failures before they impact users.
Future-Proof Data Strategy: Architect for tomorrow’s needs with blueprints for hybrid cloud, multi-model integrations, and seamless major-version upgrades.
Take Our 8-Point Cassandra Risk Assessment (Identifies Cost, Performance & Stability Gaps)
Comprehensive Apache Cassandra Consulting & Support Services
Our full lifecycle services are designed by veteran Cassandra committers and DBREs to deliver operational serenity.
1. Cassandra Strategy, Architecture & Production Deployment
We design battle-tested, cloud-agnostic architectures. This includes capacity planning for 3-5 year growth, multi-region/cloud deployment blueprints, security-hardened configurations (TLS, client-to-node encryption, Role-Based Access Control), and disaster recovery runbooks with defined RPO/RTO.
2. Cassandra Data Modeling & Query Optimization
Poor data modeling is the #1 cause of Cassandra performance issues. We conduct deep-dive data pattern analysis, design optimized tables using Query-Driven Modeling principles, implement efficient secondary indexes/materialized views, and rewrite application queries for maximum throughput and minimal latency.
3. Cassandra Performance Tuning & Benchmarking
We go beyond basic nodetool checks. Our engineers perform JVM deep dives (Garbage Collection tuning, heap pressure analysis), optimize compaction strategies (STCS, LCS, TWCS) for your workload, tune coordinator nodes and hinted handoff delays, and conduct production-simulated load testing to establish performance baselines.
4. Cassandra Migration & Modernization Services
Safely migrate from legacy RDBMS (Oracle, SQL Server), other NoSQL databases (MongoDB, DynamoDB), or older Cassandra versions. We handle schema conversion, zero-downtime data pipeline design, dual-write strategies, and comprehensive cutover validation to ensure data integrity and business continuity.
5. 24/7 Enterprise Cassandra Support & Managed Services
Our proactive Cassandra support is your insurance policy. Includes 24/7/365 monitoring and alerting (using Prometheus/Grafana with custom dashboards), performance anomaly detection, patch management, backup/restore verification, and direct access to Senior Cassandra Database Reliability Engineers (DBREs) via Slack, phone, or ticket.
6. Cassandra Health Check & Diagnostic Audit
Our signature assessment provides a crystal-clear view of your cluster’s health. We deliver a report covering cluster stability scoring, configuration compliance against 100+ best practices, security vulnerability analysis, hardware/cloud resource efficiency, and a prioritized 90-day action plan with immediate high-risk fixes.
7. High-Availability & Disaster Recovery Implementation
Design for the worst. We implement cross-data-center replication strategies, automate backup to immutable storage (AWS S3, Azure Blob), build point-in-time recovery capabilities, and conduct regular DR failover drills to ensure your recovery time objective (RTO) and recovery point objective (RPO) are met.
8. Cassandra Training & Knowledge Transfer
Empower your team. We offer role-based training for developers (data modeling, CQL best practices), administrators (day-2 operations, troubleshooting), and architects (multi-datacenter design). Includes custom runbooks and hands-on labs.
Enterprise Outcomes & Quantifiable ROI: Data for Decision Makers
Financial & Operational Impact (For CFOs & COOs):
Reduce Cloud Infrastructure Spend: Achieve 25-40% savings on AWS EC2, EBS, and data transfer costs through right-sizing, instance family optimization, and reserved capacity planning.
Eliminate Costly Downtime: Move from 99.9% to 99.99%+ availability, directly protecting revenue and avoiding six-figure penalty clauses in SLAs.
Optimize Team Productivity: Free up 20-30 hours per week for your DevOps team by offloading complex database tuning, on-call escalations, and upgrade planning to our experts.
Technical & Performance Impact (For CTOs & VPs of Engineering):
Achieve Predictable Performance: Guarantee P99 read/write latencies under 10ms for critical user-facing transactions, directly improving application UX and conversion rates.
Simplify Scalability: Handle 10x traffic growth without re-architecting by following our linear scaling blueprint—add nodes without application changes.
Mitigate Technical Debt: Resolve accumulated configuration drift and anti-patterns that create instability, preventing future outages and reducing mean-time-to-resolution (MTTR) by over 60%.
Strategic & Developer Impact (For Product & Engineering Leads):
Accelerate Feature Development: Reduce database-related sprint blockers by 70%. Developers get clear data models, performance guardrails, and on-demand expert reviews.
Enable Global Expansion: Deploy active-active multi-region clusters in 4-6 weeks, supporting new markets with local latency and data residency compliance (GDPR, CCPA).
Future-Proof Your Stack: Smoothly adopt new Cassandra features (like Java 17 support, vector search capabilities, or new storage engine options) with guided upgrade paths.
Our Proven Cassandra Consulting Methodology: The Nextbrick DBRE Framework
Phase 1: Deep Discovery & Baselining (1-2 Weeks)
Automated collection of metrics, logs, and configurations from all nodes.
Analysis of application query patterns, consistency level usage, and client drivers.
Establishment of key performance indicators (KPIs) and business SLAs.
Phase 2: Architectural Review & Design (2-3 Weeks)
Threat modeling for security and failure scenarios.
Creation of detailed architecture diagrams (network topology, rack/zone awareness).
Capacity planning model projecting costs and performance for next 24 months.
Phase 3: Implementation & Optimization (Timeline Varies)
Automated, idempotent deployment of new clusters or changes using Infrastructure-as-Code (Terraform, Ansible).
Iterative performance testing with tools like cassandra-stress or NoSQLBench, tuning based on results.
Implementation of monitoring, alerting, and backup pipelines as core infrastructure.
Phase 4: Validation & Knowledge Transfer (1-2 Weeks)
Load testing in staging that mirrors 150% of peak production traffic.
Failover and recovery drill with stakeholders observing.
Hands-on workshops and delivery of comprehensive “Day 2 Operations” manual.
Phase 5: Ongoing Support & Evolution (Continuous)
Weekly performance reports and quarterly architectural reviews.
Proactive recommendations for optimization based on trending data.
Roadmap planning for upgrades and scaling events.
Deep Technical Expertise Across the Cassandra Ecosystem
Our team includes contributors to Apache Cassandra and maintainers of key open-source monitoring tools.
Core Platform & Versions:
Apache Cassandra: Deep expertise in v3.x, v4.x, and upcoming v5.x features. Specialization in performance characteristics and upgrade paths.
Distributions & Cloud Services: DataStax Enterprise (DSE), Astra DB, Amazon Keyspaces (with guidance on limitations), Azure Managed Instance for Apache Cassandra.
Performance & Observability Stack:
Monitoring: Prometheus with Cassandra-specific exporters, Grafana dashboards for per-tenant metrics, Jaeger for distributed tracing of queries.
Profiling & Debugging: Java Flight Recorder (JFR) for hot spot analysis, tcpdump/Wireshark for protocol-level debugging, custom scripts for log analytics.
Orchestration & Infrastructure:
Deployment Automation: Kubernetes (K8ssandra operator), Terraform modules for cloud provisioning, Ansible playbooks for configuration management.
Cloud Platforms: AWS (EC2, EBS, EKS), Google Cloud (GCE, GKE), Microsoft Azure (VMs, AKS), and hybrid on-premise solutions.
Integration & Complementary Technologies:
Streaming & Analytics: Apache Kafka, Apache Pulsar, Apache Spark (for analytics sidecars).
Search & Query: Elasticsearch/OpenSearch integration via sidecar patterns, vector search implementations for AI/ML use cases.
Application Frameworks: Deep knowledge of Java drivers (sync/async), reactive stacks, and ORM pitfalls.
Evidence of Impact: Cassandra Success Stories
Global FinTech Payment Processor
Challenge: Payment transaction database (on a legacy RDBMS) experiencing 3-5 second latency spikes during peak hours, leading to cart abandonment and SLA breaches.
Our Solution: Designed and deployed a multi-region Cassandra cluster across AWS US/EU/APAC. Implemented time-series data modeling for transaction events and tunable consistency levels per query.
Quantifiable Results:
P99 write latency reduced from 3000ms to 8ms.
Achieved 99.999% availability over 24 months (less than 5 minutes total downtime).
Scaled to process 1 million transactions per minute during Black Friday.
Reduced database-related cloud costs by 35% year-over-year despite 400% data growth.
IoT Platform for Smart Manufacturing
Challenge: Ingesting and querying 5 TB/day of sensor data from 50,000 devices. Existing time-series database was unable to handle the write volume and provide fast multi-dimensional queries.
Our Solution: Architected a Cassandra-based data lake with optimized wide partitions for time-series data and Spark analytics sidecar. Implemented TTL-based automatic expiry for old data.
Quantifiable Results:
Sustainable write throughput of 500,000 events/second per cluster.
Ad-hoc queries for asset history returned in <2 seconds vs. previous 2+ minutes.
Total cost of ownership reduced by 60% versus commercial time-series DB vendors.
Enabled new predictive maintenance features due to faster query capabilities.
Major Media & Streaming Service
Challenge: User preference and viewing history database becoming a bottleneck, causing slow personalization and recommendation engine updates.
Our Solution: Migrated 200 TB of user data from MongoDB to Cassandra. Redesigned the data model to co-locate user data by region and implemented materialized views for common query patterns.
Quantifiable Results:
Personalization engine latency improved by 70%.
Successfully handled 10x user growth without re-architecting.
Data modeling changes reduced storage needs by 40% through better compression.
24/7 support partnership eliminated 3 AM on-call pages for database issues.
Client Endorsements: Trusted by Data-Intensive Enterprises
“When our Cassandra cluster showed mysterious latency spikes at 2 AM, Nextbrick’s support team had already identified the issue—a misconfigured compaction strategy—and had a fix deployed before our engineering team logged in. Their proactive Cassandra support is worth every penny.”
– Director of Platform Engineering, Fortune 500 Retail Company
“Their Apache Cassandra consulting team didn’t just give us a cluster design; they gave us a comprehensible scaling philosophy. We’ve grown from 6 to 60 nodes following their blueprint, and performance has remained perfectly linear. They transformed a complex technology into a predictable utility.”
– CTO, High-Growth AdTech Startup
“Migrating our core financial data was our biggest technology risk last year. Nextbrick’s meticulous, phased approach with multiple rollback checkpoints gave us the confidence to proceed. The cutover was flawless, and performance exceeded expectations from day one.”
– VP of Technology, Financial Services Firm
Critical Questions for Enterprise Leaders Evaluating Cassandra Expertise
1. What are the most common—and costly—mistakes you see in Cassandra deployments?
The “Big Three” are: 1) Poor data modeling (not designing tables for specific queries, leading to multi-partition reads), 2) Misconfigured hardware/cloud instances (wrong disk types, insufficient RAM for heap/off-heap), and 3) Lack of observability (no granular metrics, making troubleshooting reactive). These mistakes typically manifest as unpredictable latency, runaway cloud costs, and instability during growth. Our health check is designed to find and fix these exact issues.
2. How do you approach Cassandra performance tuning for mixed read/write workloads?
We take a layered, data-driven approach. First, we analyze the application query patterns to ensure the data model is optimal. Then, we tune JVM settings (G1GC parameters) based on the actual object allocation rates. Next, we select and configure the compaction strategy—often TWCS for time-series or LCS for update-heavy workloads. Finally, we optimize coordinator node parameters (concurrent writes/reads, native transport max threads) based on systematic load testing. We always establish a performance baseline before tuning.
3. What is included in your 24/7 Cassandra support, and how do response times work?
Our enterprise support includes: 24/7 monitoring with 5-minute SLA on critical alerts (node down, latency > SLA), direct access to senior DBREs (not Level 1 support), weekly performance reports, and patch/upgrade planning. Response time SLAs are tiered: P1 Critical (System Down): <15 minutes, 24/7. P2 High (Performance Degradation): <1 hour. P3 Medium (Configuration/Planning): <4 business hours. All incidents include a post-mortem analysis and preventative action plan.
4. We’re on an older Cassandra version (3.11). What’s the process and risk for upgrading to 4.x or 5.x?
Upgrades are low-risk with proper planning. Our process: 1) Comprehensive compatibility check of data types, drivers, and tools. 2) Staged rollout in non-production, testing all application queries. 3) Parallel run (where possible) with dual writes. 4) Phased production rollout by data center. Key benefits of upgrading include ~50% improved throughput in v4.x, Java 17 support, full-query logging for debugging, and significantly improved compaction. We’ve executed hundreds of major-version upgrades with zero data loss.
5. How does Cassandra compare to MongoDB, DynamoDB, or CockroachDB for our use case?
Cassandra excels when you need: 1) Multi-region writes with low latency, 2) Predictable linear scalability (petabyte-scale), 3) Very high write throughput (100K+ writes/sec per cluster). Consider alternatives if: You need rich, nested document queries (MongoDB may be better), you’re all-in on AWS with simple key-value needs (DynamoDB), or you require strong consistency ACID transactions across the entire dataset (CockroachDB). We provide unbiased guidance based on your specific access patterns and business requirements.
6. What does a typical engagement look like, and what are the expected costs?
Engagements start with a fixed-price Health Check ($5K-$15K) that delivers a prioritized action plan. Implementation projects range from $50K for a single-cluster optimization to $200K+ for global multi-DC deployments. Ongoing 24/7 support is typically 15-25% of your annual cloud database infrastructure spend. We provide detailed, transparent proposals after initial discovery. Most clients see full ROI on consulting fees within 3-6 months through performance gains and cost optimization.
Begin Your Journey to Cassandra Excellence
Don’t let database complexity slow your innovation. Partner with the experts who speak Cassandra fluently and understand the business imperative of data reliability.
Schedule a Technical Deep Dive with Our Lead DBRE
*Discuss your specific scalability challenges, data models, and performance goals in a 60-minute session.*
Contact Our Database Leadership Team
Phone: | Email: [email protected]
Let us show you how expert Apache Cassandra consulting and support can transform your data layer from a cost center into a relentless engine for growth.
Nextbrick Apache Cassandra Consulting | 24/7 Cassandra Support | Cassandra Performance Tuning | NoSQL Database Migration | Enterprise Database Reliability Engineering


