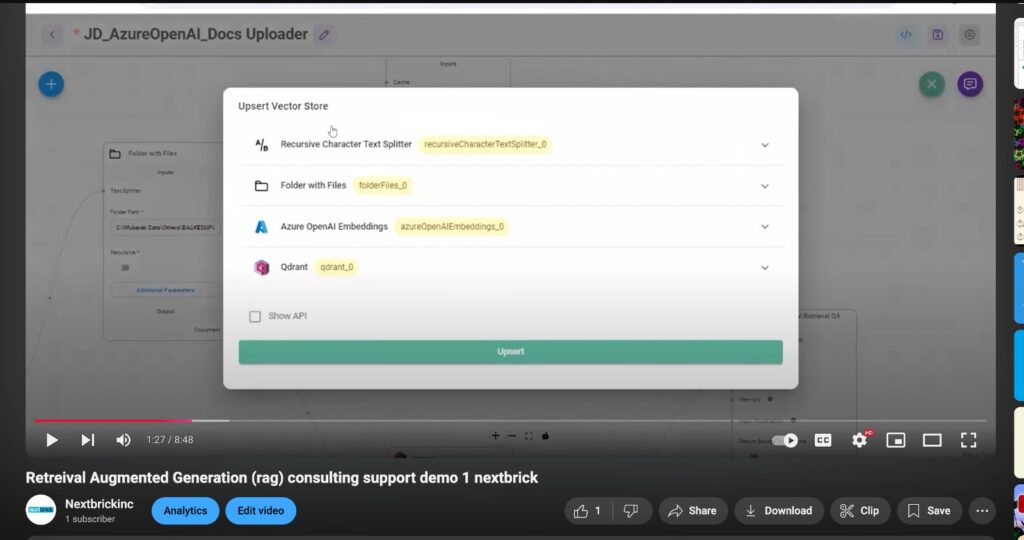
Retrieval Augmented Generation (RAG) Consulting & Support
Design, deploy, and scale production RAG systems with clear governance, measurable retrieval quality, and enterprise-ready operations.
Improved answer accuracy with grounded retrieval
Reduced hallucinations through source-backed context
Real-time knowledge updates without model retraining
Enterprise-grade policy and compliance controls
Featured Videos
Product + RAG DemosRAG Use Cases
Customer support assistants
Internal policy copilots
Knowledge search across docs and wikis
Fraud, compliance, and analytical reporting
Sales enablement and product Q&A
Multimodal retrieval for text + media